Previous articles in this series are: 1. Motivations and Methods and 2. Obtaining OpenStreetMap data.
In this third article, we’ll look at how to manipulate geodata with GeoPandas and its related libraries.
Filtering to roads within Singapore
Recall from last time that our first OSM data-gathering method, Metro Extracts, gave us too many roads: we got roads in Malaysia and Indonesia, and even some ferry lines.
>>> import geopandas as gpd
>>> df = gpd.read_file('singapore-roads.geojson')
>>> df.plot()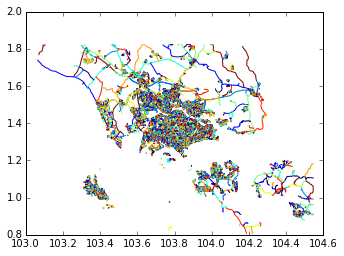
But it also gave us the administrative boundary of Singapore.
>>> admin_df = gpd.read_file('singapore-admin.geojson')
>>> # Inspecting the file we want just the first row
>>> sg_boundary = admin_df.ix[0].geometry
>>> sg_boundary # In an IPython Notebook, this will plot the Polygon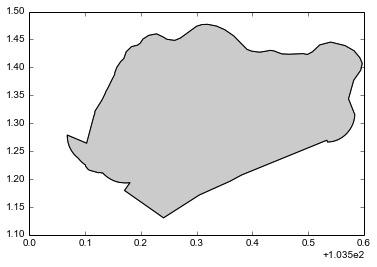
So now let’s filter to just the roads within these administrative boundaries. It’s as easy as one line:
>>> sg_roads = df[df.geometry.within(sg_boundary)]Let’s plot that to make sure we got what we want:
>>> sg_roads.plot()
Yippee! And that’s just one of the functions made available by GeoPandas. Take a look at this page to see what other kinds of manipulation you can do this way.
Clearing up a Pandas misunderstanding
Let me take this opportunity to clear up a fundamental Pandas misunderstanding I had when trying to make this work, that maybe other people might have too. My first attempt at writing this code looked like this:
>>> # Here's the change. 'Singapura' is the Malay name for Singapore
>>> sg_boundary = admin_df[admin_df.name == 'Singapura'].geometry
>>> # Let's check the type of this object
>>> type(sg_boundary)
geopandas.geoseries.GeoSeries
>>> sg_roads = df[df.geometry.within(sg_boundary)]
>>> sg_roads
I would always get precisely one road - the first road of df – back. Jake Wasserman explained to me why this was so. (You’re going to see his name
a lot in this series, because he helped me a lot with questions and code - thanks, Jake!)
sg_boundary is a GeoSeries right now, not a single value. The two vectors are thus compared pairwise -
the first item of the series df.geometry is compared with the first item of sg_boundary,
the second item with the second item, etc. In this case, of course, there is no second
item in the the sg_boundary GeoSeries. So the comparison returns False for that row, and for
all subsequent rows.
>>> df.geometry.within(sg_boundary)0 True
1 False
2 False
3 False
4 False
5 FalseAnd thus we’re left with just the first row of the GeoDataFrame df, since that’s the only one whose index value is True.
Moral of the story: be clear on whether you’re filtering against a scalar or a vector.
Something a bit more complicated
Many Singapore road names are diverse and awesome. But on occasion (quite a lot of occasions, it must be admitted), the road planners ran out of imagination and did things like this:
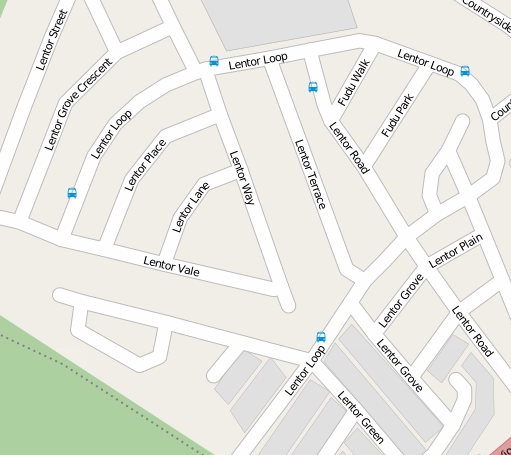 © Open Street Map contributors
© Open Street Map contributors
So each “road name” like “Lentor” represents not just one road but a potential multitude of roads. Suppose we want to give a geographic identity to each of these names - say, the centroid of all the roads with the same base name. Pandas/GeoPandas and the Shapely library make that fairly straightforward.
First, we process the full road names in the GeoDataFrame to remove “tags” like “Avenue”, “Street”, etc., and modifiers like numbers.
We call the resultant column road_name. We do a groupby on this column to gather together all the roads with the same name.
We then call an aggregate function on this groupby to merge all the LineStrings in the geometry column together into a MultiLineString.
Then we obtain the centroids of these MultiLineStrings.
Here’s the code, written by Jake Wasserman (slightly modified):
import shapely.ops
centroids = df.groupby('road_name')['geometry'].agg(
lambda x: shapely.ops.linemerge(x.values).centroid)road_name
Abingdon POINT (103.9798720899801 1.36742402697363)
Abu Talib POINT (103.92872845 1.31571555)
Adam POINT (103.8149827646084 1.331133393055676)
Adat POINT (103.8180845063596 1.328325070407948)
Adis POINT (103.8477012275151 1.300714839256321)
Admiralty POINT (103.8052864229348 1.455624490789475)(Note: The reason we have to call linemerge on x.values is because right now, shapely functions operate on lists, not numpy arrays
which are the bases for Series/GeoSeries. One day this line will be as simple as df.groupby('name')['geometry'].apply(linemerge) -
just monitor this issue.)
The output is a Pandas Series. The left hand “column” is actually an index and the right-hand column is just the values in the Series. To turn it back into a GeoDataFrame, we can do:
centroids = gpd.GeoDataFrame(centroids.reset_index())And we get this, which was what we wanted:
road_name geometry
0 Abingdon POINT (103.9798720899801 1.36742402697363)
1 Abu Talib POINT (103.92872845 1.31571555)
2 Adam POINT (103.8149827646084 1.331133393055676)
3 Adat POINT (103.8180845063596 1.328325070407948)
4 Adis POINT (103.8477012275151 1.300714839256321)Summary
I hope this post gave a good idea of how to manipulate geodata with GeoPandas (or, in the second case, a combination of Shapely and Pandas - but one day it will all be done within GeoPandas). Of course, since GeoPandas is just an extension of Pandas, all the usual slice-and-dice operations on non-geographic data are still available.
Next time, we’ll talk about another data preparation problem I had with the OpenStreetMap
data: typos in the street names, and how I cleaned them up using the fuzzywuzzy library. Till next time.