It’s been a week since I attended PyGotham 2016 in New York City. When I saw the schedule, which was packed with natural language processing talks, I knew I had to go. Plus, it was at the United Nations. How cool is it to attend a conference at the UN??!!

I had a great time attending those talks, which were uniformly excellent. I also organised a Birds of a Feather (BoF) about NLP and got to meet a lot of language-minded folk that way. Here’s a recap.
Teaching and Doing Digital Humanities with Jupyter Notebooks
Matt Lavin gave a really interesting talk combining a couple strands of his work in the digital humanities: educating people about computational DH, mainly via the medium of Jupyter notebooks, as well as his own research on dating 19th and early 20th century horror novels to answer questions like: did H. P. Lovecraft deliberately try to write in an older style than his contemporaries to make his horror more…horrorful?
Key takeaways:
While you may make questionable choices while processing the data and running your ML algorithms, it’s okay so long as you document and justify your methods so other people (and future you) can see your thought processes. Jupyter notebooks, which interleave prose and code and execution results, are great for this.
MyBinder enables you to make your Jupyter notebooks executable online, which is great for workshops, as it removes the need to get Jupyter notebook up and running on participants’ individual machines.
Summarizing documents
Many people I talked to on Saturday evening cited this as their favourite talk of the day. Mike Williams gave a masterly overview of how to do extractive summarization, starting with the “dumb” but still effective Luhn method that anyone can implement with a few lines of code. (If you’ve seen SummaryBot on Reddit, that’s how it works.) Then we worked up to Latent Dirichlet Allocation and recurrent neural networks. It was all stupendously clear and everyone felt like they came out of the talk with their brains embiggened.
Key takeaways:
When extracting bag-of-words, in future, try substituting skip-thought vectors instead.
Keras looks like a really neat way of implementing neural networks (higher-level than Theano/TensorFlow - in fact it builds on them).
Everything you always wanted to know about NLP but were afraid to ask
Steven Butler and Max Schwartz gave a solid introduction to NLP on Friday morning, covering a lot of ground from morphology through to semantics in under an hour. I think that was the first time I’d ever seen Morfessor (a classic approach to the problem of morphological segmentation) taught in an intro NLP talk! I really liked their emphasis on how knowledge of linguistics could help with NLP tasks, especially when it comes to other languages when a pre-built NLP library might not be available. If you’re looking to get started with NLP, I highly recommend this talk when the video is out!
Higher-level natural language processing with Textacy
Burton DeWilde, creator of the excellently-named library textacy, gave an overview of his NLP library. This sits atop of the also excellent spaCy library and aims to provide a nice, performant API for higher-level NLP tasks such as extracting key terms and topic modelling, with many more features planned.
A nice touch to the library is built-in data visualisations for seeing the results of an analysis. For example, you can visualise the relationship between top terms and topics after topic modelling in a termite plot with one line of code:
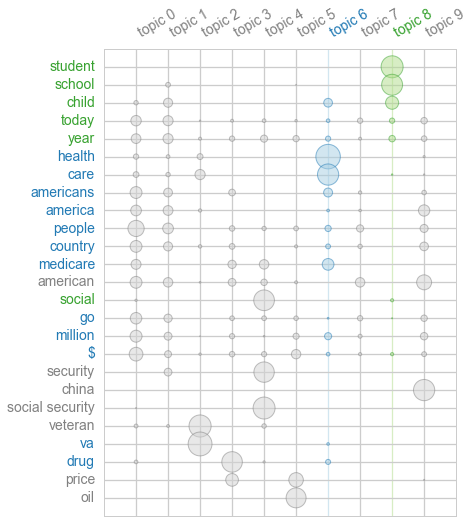
Burton also put out a call for contributors to textacy. From meeting him this weekend,
I can say he’s a really nice guy, and textacy has the makings of a great library,
so go contribute!
Others
In addition to the NLP-centric talks, there were loads of data science-themed talks. Deep learning was a big theme. Slightly less mainstream machine learning techniques like reinforcement learning and probabilistic graphical models were also covered, albeit at a simpler level.
One non-NLP/ML talk I really enjoyed was Suby Raman’s
“Making sense of 100 years of NYC opera with Python” (slides), which was more dataviz-y
and gave good tips on scraping with asyncio.
His initial blogpost about
his project got a lot of attention in music social media and even made it to
the Washington Post. It was fun to hear about the aftermath of his post.
Something he emphasised that resonated with me was the need for
domain experts to learn to root around data, since they know the really interesting
questions. Once they master the tools to answer these questions,
they’re unstoppable.
Pythons of a feather slither together…wait what?
On the first day of PyGotham, I ran into Ray Cha, who I had only met once before at Maptime Boston but quickly turned into a friend over the weekend. I told him I was thinking of doing an NLP BoF and he said he would totally participate. The risk of waiting alone and awkward in a room mitigated, I registered a time on the BoF spreadsheet (it was really hard to find a timeslot without talks an NLP person would be into) and tweeted out an announcement.
NLP folks at @PyGotham: come stop by the natural language processing BoF 3-4pm Sunday! https://t.co/RWpYYxIhne @bjdewilde #pygotham #nlproc
— Michelle Fullwood (@michelleful) July 16, 2016
Just before the actual BoF I mentioned to Ray that I thought 6-10 was about the right size for a BoF and we had 8 participants, so that was juuuuuust right. Many of them were speakers from the talks I mentioned above.
Highlights
Udi started our discussion off by sharing his implementation of a headline generator with RNNs in Keras. Not only were the results on Buzzfeed data super cool-looking, it reinforced that I should really take a good look at Keras.
Matt took us through his novel-dating project once more and the whole group brainstormed other features to add to his machine learning model, sharing their own experiences. For example, Max has been doing some really neat authorship attribution stuff with blogs and Twitter and shared his findings from that.
It turns out that Steven worked on non-concatenative morphological segmentation with Tagalog infixes, which is similar to my dissertation work on segmenting Arabic morphology! Small world!
Burton and I discussed how to train a quote extractor from prose. Textacy
currently includes one but relies on the quotes being more or less correctly
formatted, but my data is kind of messy. We were talking about
using his extractor as a baseline and getting people to annotate while reading,
then training a CRF on the resultant corpus.
Adam Palay also suggested some resources we could look
at that might already have annotated corpora.
There was also general discussion of how to handle multilingual data, data ethics, and how to get started as a beginner.
Conclusion
As someone who’s generally shy about approaching strangers in the hallway, I’ve found that giving talks is a great way to get people to come talk to me instead. Of course, if you’re shy about public speaking, that can be just as bad…so running a BoF was the happy medium for me. I got to meet some great people and share ideas, which is basically the point of going to a conference.
So thanks to the BoF participants, to PyGotham organizers, and to Ray for making my weekend!