Summary: Based on a proposal by Redditor enthusiastOfRustMayb, I built an app that takes any English text you give it, and highlights the primary-stressed syllables in bold. The idea is to help learners of English figure out where the stress goes. Try it here.
Motivation
Different languages have different systems of stress, which places prominence on certain syllables in a word and de-emphasises others. That’s (partly) why different languages have such distinctive rhythms. It’s one of the first things we learn - studies of newborn babies have shown they can distinguish the prosody of their native language from that of other languages. Correspondingly, it’s particularly difficult to unlearn one’s native prosody and relearn another. You can have the grammar down pat and the vocabulary of a native but still sound somehow “off”.
In some languages like Hungarian, the stress rule is simple - stress the first syllable. Other languages stress the second, or the final syllable, etc. In English, we’re not quite so lucky.
English has a particularly complex stress system. English mostly follows the Latin stress rule, which is dependent on the weight of a syllable - the amount of phonetic material packed into it. Stress is on the penultimate syllable if it ends with a consonant (is closed) or has a long vowel or diphthong, but retreats to the antepenultimate syllable otherwise. For example, “a.gen.da” is stressed on “gen” because it is closed. But in “as.pa.ra.gus”, the penultimate syllable “ra” is short and so the antepenultimate syllable “pa” is stressed instead. But there are loads of exceptions. Two-syllable loanwords from French usually stress the second syllable in defiance of the Latin stress rule, e.g. “adult”. Then there are words like “conflict” where the first syllable is stressed if it’s being used as a noun and the second syllable is stressed if it’s being used as a verb.
What this all amounts to is that learners of English pretty much need to memorise the stress patterns of individual words. Redditor enthusiastOfRustMayb’s idea was to assist this process by visually illustrate which syllable carries primary stress. This would be rather annoying to do manually, so I thought I’d whip together a webapp that did the heavy lifting.
Making it work
Finding the necessary data was not in itself so hard. The CMU Pronouncing Dictionary is a great resource: it has pronunciations for more than 100,000 words including obscure names. These pronunciations include stresses, but no syllable boundaries. But the Penn Phonetics Laboratory has an automated syllabifier and conveniently provides a syllabified version of CMUDICT.
However, that doesn’t solve our problem: we’re not trying to show the highlighted phonological representation of the word, but the orthographical representation. Aligning the two is tricky: think about the digraphs like <th>, silent letters like the <p> of <ptarmigan>, or the many different pronunciations of <ough> (tough, trough, through, though). It’s far from 1-to-1. In fact, it’s many-to-many.
Luckily for me, once again other smarter people have worked on this issue. Sittichai Jiampojamarn wrote the m2m-aligner, which, given pairs of orthographical and phonemic representations, learns the optimal mapping via several applications of the EM algorithm, then outputs the best alignment between each. For example, “afterthought” is aligned as follows:
| A | F | T | E:R | T:H | O | U:G | H:T |
| AE | F | T | ER | TH | AA | _ | T |
One might quibble about the exact grapheme-to-phoneme alignment, but on the syllable level, it’s pretty decent. I’ve only noticed a few problem cases.
After this, it was pretty smooth sailing: I simply applied it to the entire CMUDICT, mapped the stressed syllable in the phonemic representation to the stressed syllable of the orthographic representation, and slapped a lightweight Flask app around the whole thing. Here’s the result.
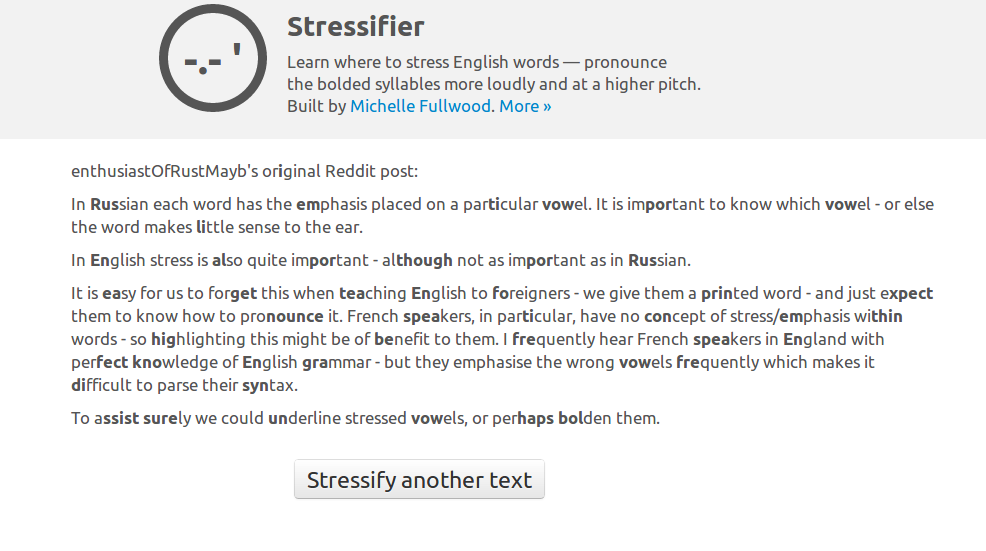
Niggling issues
There are still a few minor things that bother me. For example, “conflicts” is invariably shown with initial stress whether it is being used as a noun or a verb. To fix this problem would require doing some part-of-speech tagging - possible, but not on my priority list right now.
Another issue is whether syllables are necessarily the best unit to use as the base. Which looks better to you, the first or second column?
| particular | particular |
| teaching | teaching |
| difficult | difficult |
| hospital* | hospital |
The first column follows the standard rules of syllabification, in particular the principle of onset maximization (squeeze as many consonants into the start of a syllable as make a legal syllable), but the latter, which adhere more to the morphological structure of the word, looks more intuitive to me. Hyphenation algorithms tend to act more like Column B, and with good reason.
*“Hospital” would actually standardly be syllabified as “hos.pi.tal” but the automatic syllabification algorithm in the Penn Phonetics Toolkit appears to syllabify it as “ho.spi.tal”.
A third thing I debated about with myself was whether to italicise secondary stressed syllables, for example the “am” of “ambidextrous”, which clearly has some local prominence although primary stress is clearly on “dex”. But looking at the results, I decided there was way too much visual clutter going on for it to be useful, so I nixed it. It wouldn’t be very hard at all to add it back in, however.
Conclusion
This was a nice little project to work on and I hope someone somewhere finds it useful. After research and CSS wrangling, it only took a couple of hours to code up. The code is available on Github here. Feel free to raise an issue if you find one.
I was especially glad to have discovered the m2m-aligner through working on this, as I’ve been wanting a tool like that for some time and have other projects to apply it to. I encourage you to check it out for any alignment problems of your own.